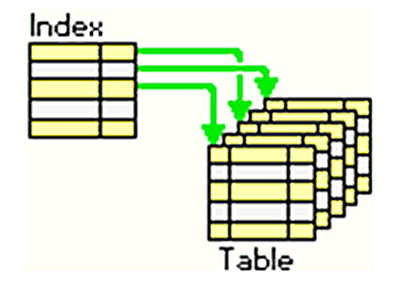
Eh bien voici une question importante qui peut porter à confusion quand on débute en modélisation des bases de données à savoir pourquoi et quand utiliser les indexes?
Nous connaissons déja qu'une table d'une BDD relationelle doit necessairement avoir une clée primaire ou primary key en anglais pour pouvoir identifier de maniere unique une entrée/une ligne ou record dans la table donc c'est grace à la clée primaire qu'on peut differencier les lignes/entrées d'une table de la BDD. Mais pour efficament faire des recherches dans les colonnes de la table, parfois on a besoin des indexes ou mieux il faut les indexer..l'indexe dans une BDD joue le meme role que l'indexe à la fin d'un livre, quand on veut trouver un argument spécifique traité dans un livre, au lieu de parcourir page par page le livre à la recherche de cet argument, il est plus facile et intuitif d'aller à l'index, de rechercher le mot clé et d'aller directement à la page ou le chapitre correspondant donc gain consequant en temps. C'est exactement le meme scenario avec l'index appliquer à une colonne d'une table dans une BDD.
Rappellons que les BDD et leur tables sont des structures de donnees stockées sur notre disque dure(bref celui du serveur des BDD lol) generalement des listes chainees, quand une colonne d'une table n'est pas indexée, la sgbd pour une recherche quelconque sur cette colonne doit scanner toute la table du début à la fin pour trouver les lignes qui respectent la requete sql, pour une table avec des millions de record, cela a un coup énorme en terme de performance par exemple immaginez facebook quand il veut afficher mon nom d'utilisateur <gallo> sur mon profil j'immagine une requete de ce genre:
Select Username from Utilisateur where userid =12345.
Si la colonne userid n'est pas indexé, il devra parcourir des millions voir milliard de record pour retourner juste ce nom d'utilisateur..ce qui est impraticable techniquement.
Donc l'index C'est une autre structure de données qu'on crée parallelement à la table qui contient les valeurs de la colonne indexée et une reference ou mieux un pointeur vers la ligne de la table à qui fait reference cette colonne, cette structure de données est ordonnée et justement on utilise les arbres binaires ou b-tree en anglais pour representer les indexes car ce sont des structures ordonnées et du coup on peut appliquer les algorithmes de recherche binaire donc je vous parlais hier et ils ont une complexité de log(n) donc plus efficace que les algorithmes lineaires ou on doit scanner toute la table.
Ajouter des indexes a aussi un cout, car un index C'est la creation d'une structure de donnees qui va en parallele avec la table originale donc occupe l'espace sur le disque dure meme chose comme les indexes d'un livre qui occupe quelques pages en plus LOL..de meme pour toutes les operations CRUD les indexes doivent etre aussi manipuler en parallele..donc il faut choisir bien les colonnes ou appliquer les indexes, le plus souvent on le fait dans les colonnes qui sont frequament utilisées pour la recherche donc dans les termes where des requetes Sql.
Happy Coding

Subscribe to Aide En Informatique's newsletter to receive the latest news and exclusive offers.
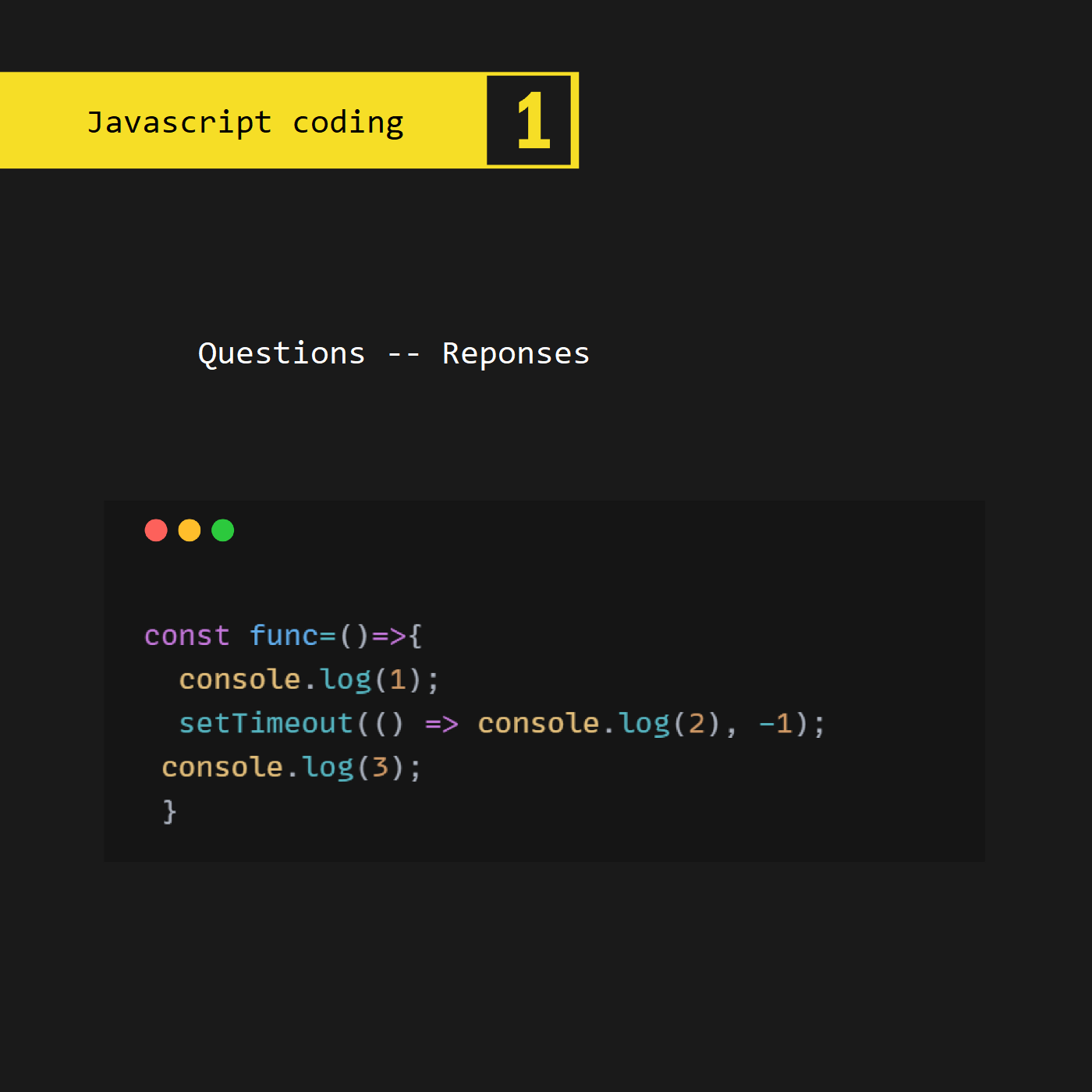
12.08.2022, 17:03
Comments: 0
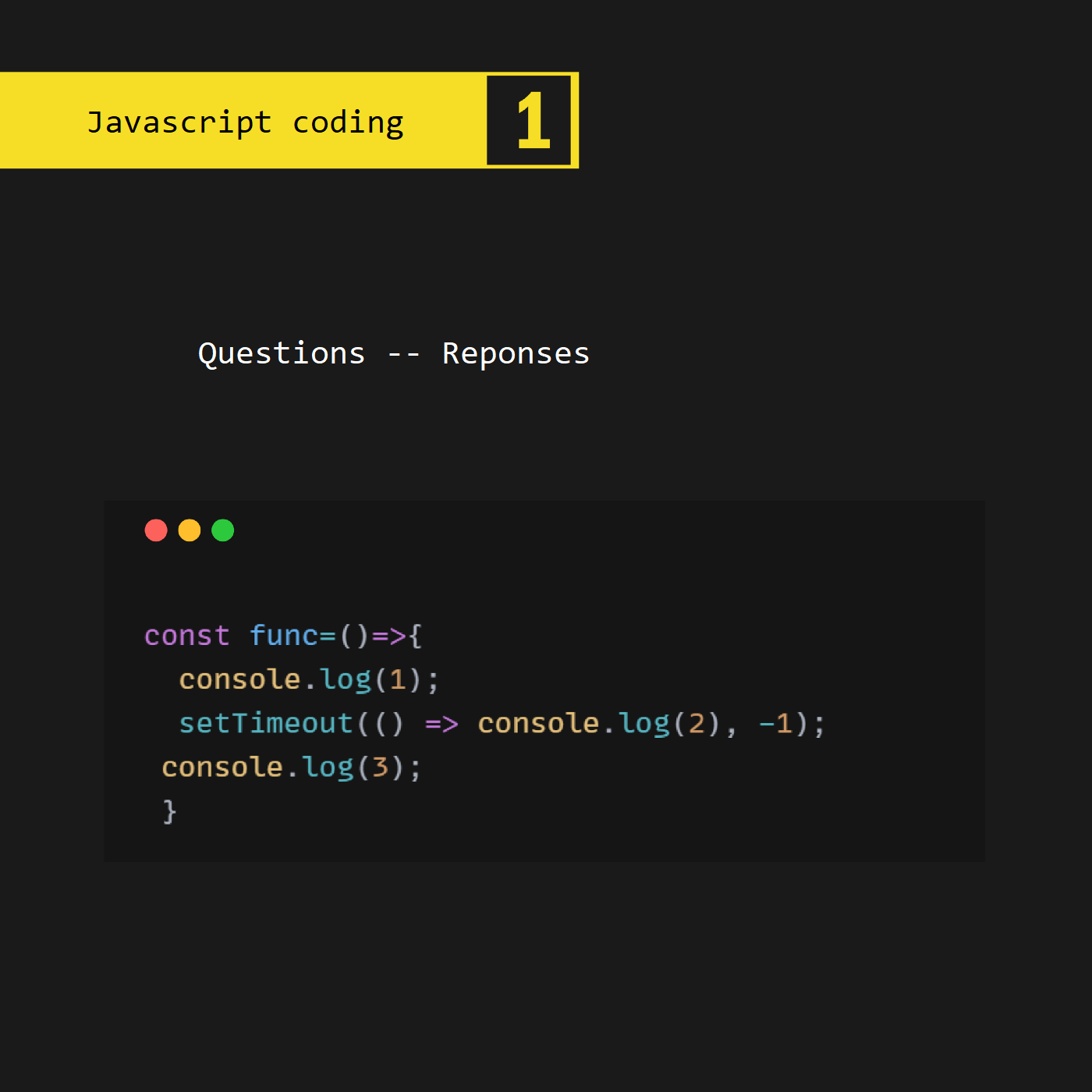
12.08.2022, 17:04
Comments: 0
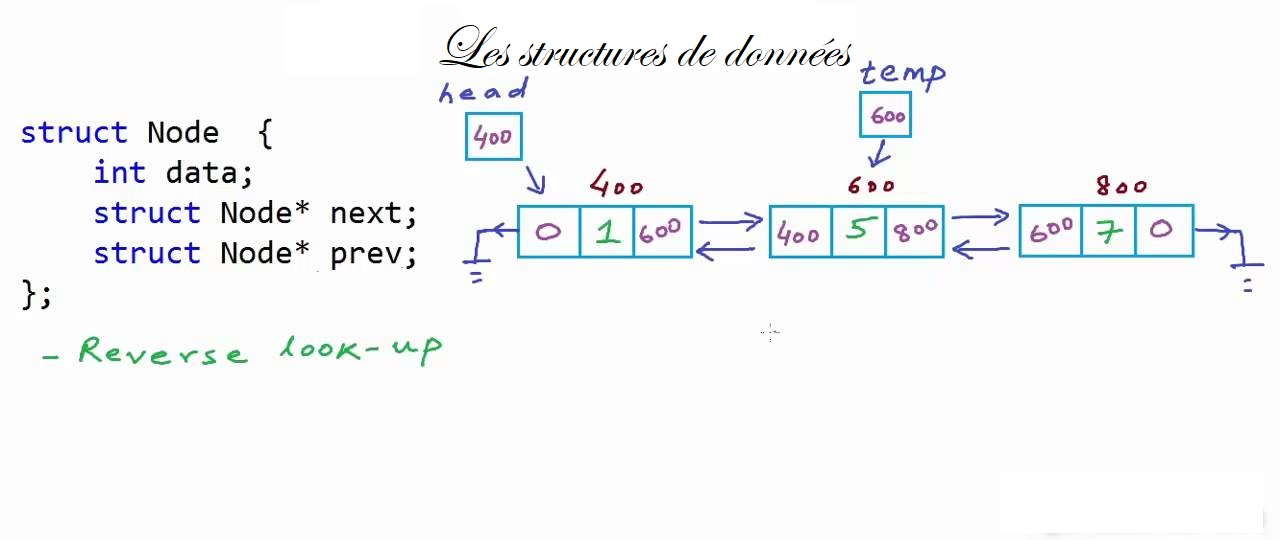
17.08.2022, 22:01
Comments: 0
31.08.2022, 17:12
Comments: 0
Bienvenue sur ITInnov-Design, l'espace des informaticiens, l'espace du codage, le lieu par excellence ou on essaye d'expliquer les choses complexes de manière Simple et surtout Terre à Terre pour permettre à tous ceux qui veulent s'avventurer dans le monde de l'informatique et du coding de ne pas etre frustré et d'entrer par la grande porte. Tous nos postes sont vos préoccupations et tout commentaires de votre part peut etre l'objet d'un autre post pour mieux eduquer, mieux approffondire et du coup n'hesitez pas à faire des questions, des remarques des suggestions dans tous nos canaux de communication de manière qu'on puisse aborder beaucoup de sujet meme de manière repetitives car, on peut expliquer la meme chose plusieurs fois de plusieurs manières differentes: en Informatqiuey, Qui Maitrise mieux son Sujet doit pouvoir l'expliquer de manière simple à un débutant Ou à une persone qui est nouveau ou ignorant sur le sujet c'est notre objectif.

LarrySig Guest
24.05.2024, 18:18
Post: Comment fonctionnent Internement les guichets automatiques ?
Orvilledop Guest
22.05.2024, 00:57
Post: Comment fonctionnent Internement les guichets automatiques ?
Orvilledop Guest
15.05.2024, 16:04
Post: Comment fonctionnent Internement les guichets automatiques ?
Franck Guest
14.05.2024, 19:34
Post: Comment deployer un site web statique sur github?